Data Pipeline Definition
A data pipeline is an automated sequence of steps that moves data from one place to another, cleaning or reshaping it along the way. Instead of someone manually exporting a spreadsheet and importing it somewhere else, a pipeline does that work continuously and without human involvement at each step.
What does a pipeline actually do?
At its simplest, a pipeline does three things: pulls data from a source, does something to it, and puts it somewhere useful. In practice that might look like: every night, grab all new orders from the ecommerce platform, match each order to a customer record in the CRM, and load the combined data into a reporting tool, ready for the team when they arrive in the morning.
The transformation step is where most of the real work happens: dropping duplicate records, standardising date formats, converting currencies, flagging missing fields. Without it, raw data from different systems rarely lines up cleanly enough to be useful.
Why does it matter?
Most businesses run several tools that don't talk to each other: a shop platform, a warehouse system, a marketing tool, a finance app. Data pipelines connect them. When a pipeline breaks or doesn't exist, teams either work from incomplete information or waste time on manual exports. When it works well, it's invisible: the right data is simply where it needs to be.
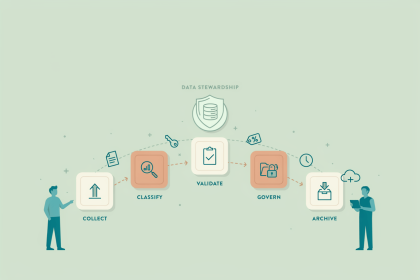
How does it relate to MDM?
Master Data Management (MDM) is concerned with making sure that core business records, things like customer profiles, product listings, and supplier details, have a single authoritative version that the rest of the organisation can trust. Data pipelines are one of the main mechanisms that feed data into and out of an MDM system.
When customer records arrive from multiple sources, a pipeline brings them together, strips out duplicates, and routes the consolidated record to the MDM system. From there, other pipelines distribute that trusted record to the tools that need it. Without pipelines, MDM becomes a manual process. Without MDM, pipelines move data efficiently but have no way of resolving conflicts between versions of the same record.
Who builds and who benefits?
Data or software engineers typically build and maintain pipelines. But the people who benefit are everyone else: analysts who need clean data to query, marketers pulling campaign reports, finance teams reconciling orders. A reliable pipeline means those people don't have to ask IT for a one-off data extract every time they need an answer.