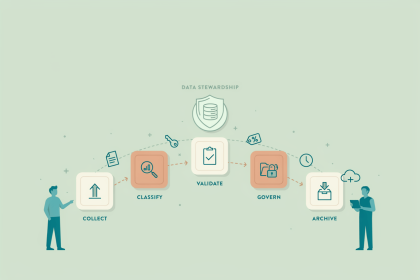
Definición de deduplicación de datos
Deduplicación de datos es el proceso de identificar registros que se refieren a la misma entidad del mundo real (un cliente, producto, proveedor o ubicación) y consolidarlos en un único registro preciso.
¿Cómo aparecen los duplicados en primer lugar?
Los duplicados se acumulan durante las operaciones comerciales normales: un cliente realiza un pedido a través de dos canales diferentes y obtiene dos cuentas, un proveedor se ingresa manualmente por dos equipos con grafías ligeramente diferentes, o un producto se importa desde múltiples fuentes con identificadores internos distintos. Los sistemas que carecen de reglas de validación o imposición de claves únicas son especialmente propensos a la duplicación con el tiempo.
¿Cómo funciona la deduplicación?
El proceso normalmente implica tres pasos. Primero, coincidencia: comparar registros usando lógica exacta o aproximada (por ejemplo, reconocer que "Müller GmbH" y "Muller GmbH" son probablemente la misma entidad). Segundo, puntuación: clasificar las coincidencias candidatas por confianza. Tercero, fusión: combinar los registros coincidentes en uno, aplicando reglas de supervivencia para decidir qué valor mantener para cada campo cuando los registros entran en conflicto. El resultado alimenta un Registro Único.
¿Cuál es la diferencia entre deduplicación y limpieza de datos?
La deduplicación se enfoca específicamente en registros duplicados. La calidad de datos y la limpieza abordan un conjunto más amplio de problemas (valores incorrectos, campos faltantes, formato inconsistente) dentro de registros individuales, independientemente de si existen duplicados. En la práctica, ambas se realizan juntas como parte de un programa de Gestión de Datos Maestros.